Belajar SKLearn - Logistic Regression

Pada latihan ini kita akan menggunakan logistic regression untuk memprediksi apakah seseorang akan membeli setelah melihat iklan sebuah produk. Dataset untuk latihan bisa Anda unduh pada tautan berikut.
Seperti biasa, setelah kita mengunggah berkas data pada Colab kita akan mengubah dataset menjadi dataframe Pandas. Jangan lupa juga untuk mengimpor library dasar.
- import pandas as pd
- from sklearn.model_selection import train_test_split
- from sklearn.preprocessing import StandardScaler
- df = pd.read_csv('Social_Network_Ads.csv')
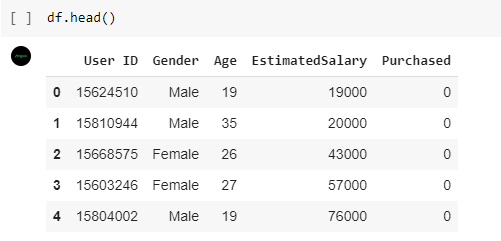
Pada cell selanjutnya gunakan fungsi head() pada dataframe untuk melihat 5 baris pertama dari dataset.
- df.head()
Hasil dari fungsi df.head() seperti di bawah ini.
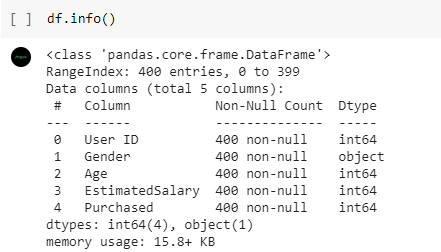
Kita juga perlu melihat apakah ada nilai yang kosong pada setiap atribut dengan menggunakan fungsi info(). Dapat dilihat bahwa nilai pada semua kolom sudah lengkap.
- df.info()
Sedangkan tampilan hasil dari fungsi df.info() sebagai berikut.
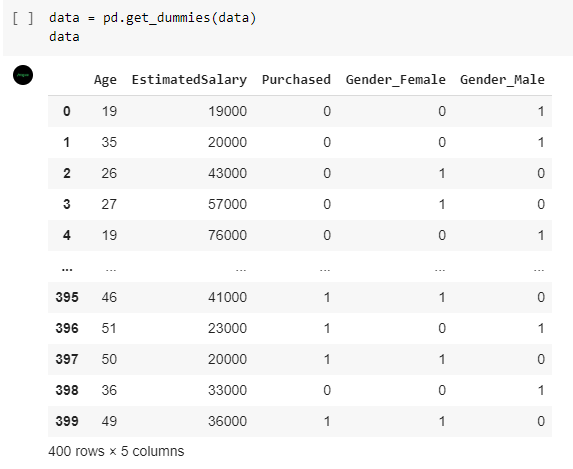
Pada dataset terdapat kolom ‘User ID’. Kolom tersebut merupakan atribut yang tidak penting untuk dipelajari oleh model sehingga perlu dihilangkan. Untuk menghilangkan kolom dari dataframe, gunakan fungsi drop.
- data = df.drop(columns=['User ID'])
- data = pd.get_dummies(data)
- data
Ketika kode di atas dijalankan hasilnya seperti di bawah ini.
Kemudian kita pisahkan antara atribut dan label.
- predictions = ['Age' , 'EstimatedSalary' , 'Gender_Female' , 'Gender_Male']
- X = data[predictions]
- y = data['Purchased']
Jangan lupa untuk membagi data menjadi train set dan test set yang dapat dilakukan dengan fungsi train_test_split yang disediakan SKLearn.
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
Setelah membagi data, kita buat model dengan membuat sebuah objek logistic regression. Setelah model dibuat, kita bisa melatih model kita dengan train set menggunakan fungsi fit().
- from sklearn import linear_model
- model = linear_model.LogisticRegression()
- model.fit(X_train, y_train)
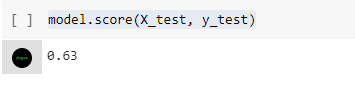
Setelah model dilatih, kita bisa menguji akurasi model pada test set dengan memanggil fungsi score() pada objek model.
- model.score(X_test, y_test)
Sehingga hasilnya sebagai berikut.